
Он обладает следующими достоинствами:
Надеюсь, следующий ниже материал поможет по-новому взглянуть на ряд известных фактов, а также вызовет желание лично проверить пару-тройку возникших по ходу чтения мыслей. Дерзайте!
С уважением, Сергей Деревяго.
В чем же польза статистики применительно к сжатию данных? Дело в том, что уже сжатые, т.н. "несжимаемые" файлы обладают вполне определенными свойствами. Как минимум, не позволяющими себя сжать еще больше.
Удивительно, но факт. На первый взгляд подобного рода файлы можно представить себе в виде генератора случайных чисел, раз за разом выдающего все возможные байты с одинаковой вероятностью.
Значит ли это, что генератор может выдать файл, состоящий из одних нулей? Да, может: раз может выдать один ноль, то может и два нуля друг за другом... Всяко бывает.
Вот только "не может"! Т.к. полностью нулевой файл прекрасно сжимается любым архиватором и абсолютно не подходит на роль несжимаемого -- парадокс!
И является сей парадокс тем самым статистическим зазором, позволяющим использовать вполне предсказуемые свойства "несжимаемых". Как именно? Хороший вопрос!
Если мы начнем анализировать подобный файл байт за байтом, то практически ничего не выиграем: все, абсолютно все байты в нем встретятся с примерно одинаковой вероятностью.
А если брать по 32 байта сразу? Ха! Да ни один известный файл на нашей Планете не может содержать ВСЕ возможные 256-битные комбинации!!!
Интересовались когда-нибудь Криптографией? Ну, чтобы долго не искать, приведу широко известную в узких кругах цитату:
|
Одним из следствий второго закона термодинамики является то, что для представления информации необходимо некоторое количество энергии. Запись одиночного бита, изменяющая состояние системы, требует количества энергии не меньше чем kT; где Т - абсолютная температура системы и k - постоянная Больцмана.
Приняв, что k = 1,38*10-16 эрг/K, и что температура окружающей вселенной 3,2K, идеальный компьютер, работая при 3,2K, потреблял бы 4,4*10-16 эрга всякий раз, когда он устанавливает или сбрасывает бит. Работа компьютера при температуре более низкой, чем температура космического пространства, потребовала бы дополнительных расходов энергии для отвода тепла. Далее, энергия, излучаемая нашим Солнцем за год, составляет около 1,21*1041 эргов. Это достаточно для выполнения 2*1056 перемен бита в нашем идеальном компьютере, а этого, в свою очередь, хватит для того, что бы 187-битовый счетчик пробежал все свои значения. Если мы построим вокруг Солнца сферу Дайсона и перехватим без всяких потерь всю его энергию за 32 года, мы сможем получить компьютер для вычисления 2192 чисел. Конечно, энергии для проведения каких-нибудь полезных вычислений с этим счетчиком уже не останется. Но это только одна жалкая звезда. При взрыве типичной сверхновой выделяется около 1051 эргов. (В сто раз больше энергии выделяется в виде нейтрино, но пусть они пока летают). Если всю эту энергию удастся бросить на одну вычислительную оргию, то все свои значения сможет принять 219-битовый счетчик. Эти числа не имеют ничего общего с самой аппаратурой, они просто показывают максимальные значения, обусловленные термодинамикой. Кроме того, эти числа наглядно демонстрируют, что вскрытие грубой силой 256-битового ключа будет невозможно, пока компьютеры построены из обычной материи и располагаются в обычном пространстве. |
Ну как, понятно к чему идем? Да, именно так: вместо тех самых, очередных 256 бит файла мы можем просто записывать номер одной из тех уникальных 256-битовых комбинаций, что вообще в нем встретились. И вуаля -- есть сжатие!
Или нет? Ну что ж, читайте дальше...
p*log2(p). Для двух элементов с вероятностями p и 1-p соответственно оно дает нам следующие результаты:
| p | бит на символ |
| 0.12 | 0.5294 |
| 0.24 | 0.7950 |
| 0.36 | 0.9427 |
| 0.48 | 0.9988 |
| 0.50 | 1.0000 |
Т.е. если в нашем файле битики 0 и 1 встречаются с вероятностями 0.12 и 0.88 соответственно, то чисто теоретически мы сможем их сжать до 0.5294 бит на каждый -- не лучше! Например, последовательность из 1024 бит будет сжата до:
| p | бит |
| 0.12 | 543 |
| 0.24 | 815 |
| 0.36 | 966 |
| 0.48 | 1023 |
| 0.50 | 1024 |
Как можно видеть, 0.12 вероятность превращает 1024 бит в 543, а 0.50 не дает вообще ничего. Даже теоретически!
Ну, нет так нет...
Вот только, если представить себе 1024 бит с 512 случайно рассыпанными единичками как количество сочетаний Cnk=n!/(k!*(n-k)!) для n и k равных 1024 и 512 соответственно, то получится
4 481 254 552 098 970 810 024 164 850 481 333 180 015 307 859 067 736 994 416 087 899 404 773 706 611 439 644 791 084 140 072 914 060 346 169 434 018 618 602 803 007 501 672 376 496 858 699 873 983 626 616 062 471 675 851 505 572 102 025 159 335 401 090 559 027 828 522 105 229 760 114 900 377 047 750 101 938 511 604 932 553 647 462 517 438 444 513 648 765 332 694 500 283 328 402 213 868 763 956 573 913 670
Легко видеть, что это всего лишь 1019 бит, что МЕНЬШЕ ТЕОРЕТИЧЕСКОГО ПРЕДЕЛА!!!
Расширим для удобства предыдущую таблицу значениями n, k и количеством бит, необходимым для представления значения Cnk:
| p | бит | Cnk бит | n | k |
| 0.12 | 543 | 538 | 1024 | 123 |
| 0.24 | 815 | 810 | 1024 | 246 |
| 0.36 | 966 | 961 | 1024 | 369 |
| 0.48 | 1023 | 1018 | 1024 | 492 |
| 0.50 | 1024 | 1019 | 1024 | 512 |
Да, все именно так, как кажется: прямой наивный подсчет количества возможных сочетаний позволяет сжимать последовательности бит сильнее теоретического предела Арифметического кодирования! Эта простая полезная мысль многие годы занимала мое внимание, заставляя экспериментировать в поисках практически полезной реализации.
Конечно, все не так просто, ведь кроме значения Cnk нужно где-то хранить и сами n, k. И, скажем, только для k требуется не менее 10 бит пространства (0<=k<=n, при n=1024), что в худшем случае C1024512 дает нам 1019+10=1029 бит и очевидно больше исходных 1024. Но ведь и Арифметическое кодирование точно так же где-то обязано хранить свой "словарь" вероятностей, т.е. состоятельность метода даже на второй взгляд не вызывает сомнений.
66 69 6C 65, т.е. 32 бита: 1100110 1101001 1101100 1100101. Давайте начнем с нуля и будем шаг за шагом двигаться вверх/вниз для 1/0 соответственно:
Тем самым последовательность бит мы представляем себе в виде некоторого пути из точки (0, 0) в (n, -n+k*2).
Каков диапазон всех возможных путей? Очевидно, это треугольник от единиц вверху до нулей снизу:

А всех путей, приходящих в ту же самую точку?
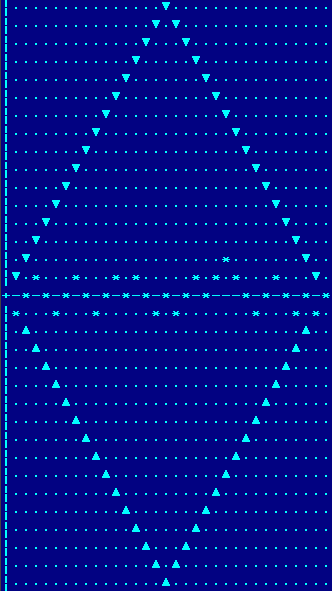
В нашем случае это большой ромб, лишь очень малую часть которого занимает исходная последовательность. А ромбом он является потому, что количество нулей в последовательности оказалось равно количеству единиц, и мы снова пришли в ноль по оси Y.
Для иллюстрации более общего случая возьмем само слово "ромб":
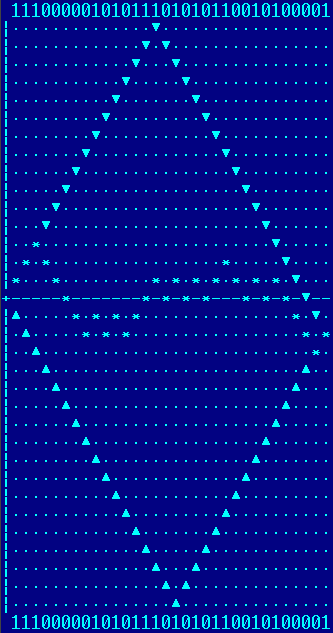
Здесь пути уже ограничены параллелограммом.
Для начала построим треугольник для всех возможных последовательностей длиной не более восьми бит:
: 0 1 2 3 4 5 6 7 8 8: 1 7: 1 6: 1 8 5: 1 7 4: 1 6 28 3: 1 5 21 2: 1 4 15 56 1: 1 3 10 35 0: 1 2 6 20 70 -1: 1 3 10 35 -2: 1 4 15 56 -3: 1 5 21 -4: 1 6 28 -5: 1 7 -6: 1 8 -7: 1 -8: 1 : 0 1 2 3 4 5 6 7 8 |
Не страшно, правда? Теперь для шестнадцати:
: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 16: 1 15: 1 14: 1 16 13: 1 15 12: 1 14 120 11: 1 13 105 10: 1 12 91 560 9: 1 11 78 455 8: 1 10 66 364 1820 7: 1 9 55 286 1365 6: 1 8 45 220 1001 4368 5: 1 7 36 165 715 3003 4: 1 6 28 120 495 2002 8008 3: 1 5 21 84 330 1287 5005 2: 1 4 15 56 210 792 3003 11440 1: 1 3 10 35 126 462 1716 6435 0: 1 2 6 20 70 252 924 3432 12870 -1: 1 3 10 35 126 462 1716 6435 -2: 1 4 15 56 210 792 3003 11440 -3: 1 5 21 84 330 1287 5005 -4: 1 6 28 120 495 2002 8008 -5: 1 7 36 165 715 3003 -6: 1 8 45 220 1001 4368 -7: 1 9 55 286 1365 -8: 1 10 66 364 1820 -9: 1 11 78 455 -10: 1 12 91 560 -11: 1 13 105 -12: 1 14 120 -13: 1 15 -14: 1 16 -15: 1 -16: 1 : 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Вроде бы тоже влезает в экран. А вот для 32 и более уже имеет смысл использовать отдельный файл -- зрелище, я вам скажу, не для слабонервных!
Между тем, нашей целью являются не вообще все пути, а только те, что приходят в нужную точку. Например, для C168 треугольник становится ромбом:
: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 8: 1 7: 1 9 6: 1 8 45 5: 1 7 36 165 4: 1 6 28 120 495 3: 1 5 21 84 330 1287 2: 1 4 15 56 210 792 3003 1: 1 3 10 35 126 462 1716 6435 0: 1 2 6 20 70 252 924 3432 12870 -1: 1 3 10 35 126 462 1716 6435 -2: 1 4 15 56 210 792 3003 -3: 1 5 21 84 330 1287 -4: 1 6 28 120 495 -5: 1 7 36 165 -6: 1 8 45 -7: 1 9 -8: 1 : 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
И, соответственно, параллелограммом для C165:
: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 5: 1 4: 1 6 3: 1 5 21 2: 1 4 15 56 1: 1 3 10 35 126 0: 1 2 6 20 70 252 -1: 1 3 10 35 126 462 -2: 1 4 15 56 210 792 -3: 1 5 21 84 330 1287 -4: 1 6 28 120 495 2002 -5: 1 7 36 165 715 3003 -6: 1 8 45 220 1001 4368 -7: 1 9 55 286 1365 -8: 1 10 66 364 -9: 1 11 78 -10: 1 12 -11: 1 : 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
А сейчас самое время вернуться к нашим картинкам. Еще раз отметим, что, несмотря на внушительные размеры параллелограммов, необходимых для полного подсчета всех возможных вариантов по треугольнику, сами по себе последовательности бит довольно слабо отклоняются от линии (помечена плюсиками), соединяющей начальные/конечные точки:

и

Что позволяет нам ввести ограничительные линии и перейти к Ограниченному Треугольнику Паскаля:

и

Что это дает? Сравним хвосты треугольников, полного и ограниченного:
"file" полный, C(32, 16)"file" ограниченный, C(32, 16, 2) |
"ромб" полный, C(32, 15)"ромб" ограниченный, C(32, 15, 3) |
|||
| вариантов | бит | вариантов | бит | |
| полный | 601080390 | 29.16 | 565722720 | 29.08 |
| ограниченный | 28697814 | 24.77 | 151268480 | 27.17 |
Удивительно, но факт: даже такое примитивное ограничение сразу же заметно уменьшает количество вариантов и, как следствие, количество бит, необходимых для их хранения (на 15% и 7%). И что немаловажно, при этом существенным образом уменьшается количество узлов треугольника, подлежащих расчету, -- в десятки раз падает время работы и используемый объем памяти!
cpt.
В идеале все очень просто: знай себе записывай номер варианта, приходящего в данную точку, да (n, k, d) не забывай сохранять -- они же нам точку определяют! Но, к сожалению, прямое сохранение параметров требует слишком много пространства, т.к. они обусловлены довольно широкими рамками:
0 <= k <= n0 <= d <= n/2
n в самом начале кодирования, как параметр командной строки. Значение NN (n=2^NN) сохраняется в имени созданного файла, чтобы пользователю не пришлось его вводить при декодировании.
d для всего блока сразу. Как показала практика, сохранение отдельного значения d для каждого пути не имеет особого смысла.
k для каждого пути в блоке, но использовать для этого примитивные процедуры сжатия: запоминать фактические минимальные/максимальные значения в блоке и записывать k уже в их пределах.
Ну и стоит отметить, что некоторые моменты будут в дальнейшем усовершенствованы (уже проверено несколько хороших идей, но усложнять proof-of-concept реализацию не имеет особого смысла). Суть алгоритма -- это сохранение номера пути вместо самого пути (одного из всех путей, приходящих в данную точку и подсчитанных с помощью Ограниченного Треугольника Паскаля). Суть безусловно останется неизменной.
Для начала, возьмем какой-нибудь файл средней паршивости и попытаемся его сжать самым обычным Zip-ом:
| размер | отношение | разность | |
| .html | 88819 | 1.0000 | 0 |
| .html.zip | 26516 | 0.2985 | 62303 |
| .html.cpt8 | 88120 | 0.9921 | 699 |
html.zip показал вполне хорошие результаты: 30% и 62303 сэкономленных байт! А вот .cpt8 с его 99% и 699...
ВСЁ, ДАЛЬШЕ МОЖНО УЖЕ НЕ ЧИТАТЬ!!!
Хотя... В качестве жалкого оправдания вспомним, что cpt работает на уровне битиков и вовсе не чужд теоретическим их пределам. В использованном для пробы файле оказалось 710552 битиков при 352721 единичке, что дает нам вероятность p=0.4964 и теоретический предел сжатия 0.999966. Ага! Расширим табличку:
| размер | отношение | разность | |
| .html | 88819 | 1.000000 | 0 |
| .html.zip | 26516 | 0.298540 | 62303 |
| .html.cpt8 | 88120 | 0.992130 | 699 |
| p=0.4964 | 88816 | 0.999966 | 3 |
Вдумайтесь: 699 из 3 возможных -- песня!!! Если конечно верить в эти теории заговора...
Но зачем слепо верить, если можно понять?! Суть в том, что и cpt и "заговоры" работают на уровне бит, а не кортежей байт. Т.е. если весь файл будет состоять из одного только байта 01010101, то cpt8 воспримет его как жутко несжимаемый C256128 (p=0.5), а Zip ничтоже сумняшеся втопчет в самое что ни на есть... Ну, вы видели, можете сами представить!
Еще пример, сложнее. Представим себе действительно несжимаемый файл, в котором равномерно и абсолютно случайно с вероятностью 50% рассыпаны единички. Здесь все уже честно: ни на уровне битиков, ни на уровне байтиков, ни даже на Уровне Последовательностей Слов с ним ничего нельзя сделать: все, что встречается -- повторится не чаще, чем можно бы ожидать от равномерного распределения! А теперь прицепим его самого за собой: любой архиватор, заметивший равенство половин, мгновенно урежет в два раза! А остальные... Все остальные точно так же ничего не смогут поделать: равномерное равновероятное распределение -- это вам не Zip запускать!
Так что же все-таки может сжать cpt так, как оно недоступно сферическому Zip в вакууме? Например, это "случайные" файлы. Грубо говоря, это данные с НЕ повторяющимися последовательностями бит. И они обязательно где-то встречаются в дикой природе!
Но так как мы милостей от Природы не ждем, самое время предъявить (псевдо) случайные файлы, с (приблизительными) вероятностями 12%, 24%, 36% и 48% соответственно:
| rnd.131072.12 | rnd.131072.24 | rnd.131072.36 | rnd.131072.48 | ||
| orig | размер | 131072 | 131072 | 131072 | 131072 |
| .zip | размер | 81551 | 108043 | 124616 | 131216 |
| отношение | 0.6222 | 0.8243 | 0.9507 | 1.0011 | |
| разность | 49521 | 23029 | 6456 | -144 | |
| .cpt12 | размер | 69379 | 104300 | 123631 | 130967 |
| отношение | 0.5293 | 0.7957 | 0.9432 | 0.9992 | |
| разность | 61693 | 26772 | 7441 | 105 | |
| p | размер | 69385 | 104208 | 123560 | 130921 |
| отношение | 0.5294 | 0.7950 | 0.9427 | 0.9988 | |
| разность | 61687 | 26864 | 7512 | 151 | |
Ну вот, совсем другое дело: Zip проиграл по всем позициям! А в качестве упражнения читателю предлагается собственноручно посрамить любимый свой архиватор означенным выше способом.
Коль скоро практически полезный результат нами уже получен, имеет смысл сравнить степени сжатия cpt друг с другом. Не секрет, что увеличение n в два раза самым существенным образом сказывается на производительности и объеме используемой памяти: уже начиная с cpt13 они уверенно уходят за рамки разумного. Стоит ли игра свеч?!
В следующих ниже таблицах были использованы те же самые файлы плюс один .doc, мирно лежавший неподалеку. Итак:
Размеры файлов:
| rnd.12 | rnd.24 | rnd.36 | rnd.48 | .doc | |
| orig | 131072 | 131072 | 131072 | 131072 | 43520 |
| cpt5 | 74215 | 108587 | 127861 | 135948 | 19294 |
| cpt6 | 72092 | 106726 | 126159 | 133122 | 18937 |
| cpt7 | 70680 | 105370 | 124741 | 131999 | 18690 |
| cpt8 | 69901 | 104805 | 124161 | 131435 | 18667 |
| cpt9 | 69598 | 104494 | 123846 | 131197 | 18884 |
| cpt10 | 69486 | 104368 | 123710 | 131047 | 19190 |
| cpt11 | 69401 | 104330 | 123654 | 130993 | 19615 |
Отношение сжатого файла к исходному:
| rnd.12 | rnd.24 | rnd.36 | rnd.48 | .doc | |
| orig | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| cpt5 | 0.5662 | 0.8285 | 0.9755 | 1.0372 | 0.4433 |
| cpt6 | 0.5500 | 0.8143 | 0.9625 | 1.0156 | 0.4351 |
| cpt7 | 0.5392 | 0.8039 | 0.9517 | 1.0071 | 0.4295 |
| cpt8 | 0.5333 | 0.7996 | 0.9473 | 1.0028 | 0.4289 |
| cpt9 | 0.5310 | 0.7972 | 0.9449 | 1.0010 | 0.4339 |
| cpt10 | 0.5301 | 0.7963 | 0.9438 | 0.9998 | 0.4409 |
| cpt11 | 0.5295 | 0.7960 | 0.9434 | 0.9994 | 0.4507 |
Разность предыдущего и следующего файлов:
| rnd.12 | rnd.24 | rnd.36 | rnd.48 | .doc | |
| orig | 0 | 0 | 0 | 0 | 0 |
| cpt5 | 56857 | 22485 | 3211 | -4876 | 24226 |
| cpt6 | 2123 | 1861 | 1702 | 2826 | 357 |
| cpt7 | 1412 | 1356 | 1418 | 1123 | 247 |
| cpt8 | 779 | 565 | 580 | 564 | 23 |
| cpt9 | 303 | 311 | 315 | 238 | -217 |
| cpt10 | 112 | 126 | 136 | 150 | -306 |
| cpt11 | 85 | 38 | 56 | 54 | -425 |
Как можно видеть, каждый следующий шаг приносит все меньше пользы, а пример реального .doc-а доказывает, что .cpt9 вовсе не обязательно окажется лучше .cpt8!
.html средней паршивости... Никак из головы не выходит!
И что ведь обидно -- все просто, как грабли! Да, попались нам байтики с нехорошо рассыпанными битиками, однако разных там байтиков не так уж и много. Вот, например, что будет, если из каждого следующего байта вычесть значение предыдущего?
| байт | разность | по модулю |
| 60 | 60 | 60 |
| 104 | 44 | 44 |
| 116 | 12 | 12 |
| 109 | -7 | 7 |
| 108 | -1 | 1 |
| 62 | -46 | 46 |
| 13 | -49 | 49 |
| 10 | -3 | 3 |
| 13 | 3 | 3 |
| 10 | -3 | 3 |
| 60 | 50 | 50 |
| 104 | 44 | 44 |
| 101 | -3 | 3 |
| 97 | -4 | 4 |
| 100 | 3 | 3 |
| 62 | -38 | 38 |
| 13 | -49 | 49 |
| 10 | -3 | 3 |
| 32 | 22 | 22 |
| 32 | 0 | 0 |
| 60 | 28 | 28 |
| 109 | 49 | 49 |
| 101 | -8 | 8 |
| 116 | 15 | 15 |
| 97 | -19 | 19 |
| 32 | -65 | 65 |
| 104 | 72 | 72 |
| 116 | 12 | 12 |
| 116 | 0 | 0 |
| 112 | -4 | 4 |
| 45 | -67 | 67 |
| 101 | 56 | 56 |
| среднее: | 26.22 | |
Как можно видеть, среднее по модулю отклонение составляет всего лишь 26.22, а в честно распределенном файле (вы же не забыли про p=0.4964?) вполне можно было бы ожидать все 128!
Ну так что стоит нам преобразовать файл перед сжатием, заменив каждый следующий байт его отклонением от предыдущего? Отклонение будем считать неотрицательным, сразу в две стороны:
разн. откл. 0 0 -1 1 1 2 -2 3 2 4 -3 5 3 6 -4 7 4 8 ... |
И даже не так! К чему эти равномерно растущие отклонения, когда мы стремимся получить минимально возможное количество единиц в байте? Давайте сразу же подставлять удобные нам значения:
отклонение значение 0 00000000 0 00000000 1 00000001 1 00000001 2 00000010 2 00000010 3 00000011 4 00000100 4 00000100 8 00001000 5 00000101 16 00010000 6 00000110 32 00100000 7 00000111 64 01000000 8 00001000 128 10000000 9 00001001 3 00000011 10 00001010 5 00000101 11 00001011 6 00000110 12 00001100 9 00001001 13 00001101 10 00001010 14 00001110 12 00001100 15 00001111 17 00010001 ... |
Ну вот и все. Смотрим, что вышло:
| исходный байт | преобразованный | ||
| 60 | 00111100 | 102 | 01100110 |
| 104 | 01101000 | 194 | 11000010 |
| 116 | 01110100 | 65 | 01000001 |
| 109 | 01101101 | 10 | 00001010 |
| 108 | 01101100 | 1 | 00000001 |
| 62 | 00111110 | 208 | 11010000 |
| 13 | 00001101 | 30 | 00011110 |
| 10 | 00001010 | 16 | 00010000 |
| 13 | 00001101 | 32 | 00100000 |
| 10 | 00001010 | 16 | 00010000 |
| 60 | 00111100 | 45 | 00101101 |
| 104 | 01101000 | 194 | 11000010 |
| 101 | 01100101 | 16 | 00010000 |
| 97 | 01100001 | 64 | 01000000 |
| 100 | 01100100 | 32 | 00100000 |
| 62 | 00111110 | 137 | 10001001 |
| 13 | 00001101 | 30 | 00011110 |
| 10 | 00001010 | 16 | 00010000 |
| 32 | 00100000 | 25 | 00011001 |
| 32 | 00100000 | 0 | 00000000 |
| 60 | 00111100 | 56 | 00111000 |
| 109 | 01101101 | 39 | 00100111 |
| 101 | 01100101 | 17 | 00010001 |
| 116 | 01110100 | 129 | 10000001 |
| 97 | 01100001 | 7 | 00000111 |
| 32 | 00100000 | 139 | 10001011 |
| 104 | 01101000 | 177 | 10110001 |
| 116 | 01110100 | 65 | 01000001 |
| 116 | 01110100 | 0 | 00000000 |
| 112 | 01110000 | 64 | 01000000 |
| 45 | 00101101 | 149 | 10010101 |
| 101 | 01100101 | 83 | 01010011 |
| ∑ 1 | 107 | 76 | |
| p | 0.4180 | 0.2969 | |
Очень хорошо! А сейчас преобразуем весь файл и снова попробуем:
| исходный файл | преобразованный | ||||||
| размер | отношение | разность | размер | отношение | разность | ||
| .html | 88819 | 1.000000 | 0 | .html.trm | 88819 | 1.000000 | 0 |
| .html.zip | 26516 | 0.298540 | 62303 | .html.trm.zip | 32050 | 0.360846 | 56769 |
| .html.cpt8 | 88120 | 0.992130 | 699 | .html.trm.cpt8 | 75888 | 0.854412 | 12931 |
| p=0.4964 | 88816 | 0.999966 | 3 | p=0.2771 | 75628 | 0.851484 | 13191 |
Конечно же, с Zip-ом и близко мы не сравнились! Но интересен сам факт: даже самое примитивное преобразование перед сжатием сразу же дало нам 0.2771 вероятность и, как следствие, 14% улучшение сжатия. А вот Zip-у, естественно, поплохело: +21%!
Ну и на всякий случай отметим, что панацеей оно отнюдь не является, т.к. будучи примененным к произвольному файлу, может даже ухудшить его структуру:
> cptrm c some.doc 0.1432 0.1879 > cptest c8 some.doc > cptest c8 some.doc.trm |
Размер итогового some.doc.trm.cpt8 составляет 22649, что много хуже просто some.doc.cpt8 с его 18667.
Отметим сразу, что примитивный способ прямого битового представления номера символа не работает, т.к. количество символов как правило не является степенью 2. Как быть? Все просто: отметим битами позиции символов!
Если, допустим, наш многострадальный .html начинается с байт 3C 68 74 6D 6C 3E 0D 0A, то разбиение их по два бита даст нам значения-символы от 0 до 3:
| байты | 00111100 | 01101000 | 01110100 | 01101101 | 01101100 | 00111110 | 00001101 | 00001010 | ||||||||||||||||||||||||
| пары | 00 | 11 | 11 | 00 | 01 | 10 | 10 | 00 | 01 | 11 | 01 | 00 | 01 | 10 | 11 | 01 | 01 | 10 | 11 | 00 | 00 | 11 | 11 | 10 | 00 | 00 | 11 | 01 | 00 | 00 | 10 | 10 |
| символы | 0 | 3 | 3 | 0 | 1 | 2 | 2 | 0 | 1 | 3 | 1 | 0 | 1 | 2 | 3 | 1 | 1 | 2 | 3 | 0 | 0 | 3 | 3 | 2 | 0 | 0 | 3 | 1 | 0 | 0 | 2 | 2 |
Отметим единичками позиции 0-символов, а нулями все остальные:
| символы | 0 | 3 | 3 | 0 | 1 | 2 | 2 | 0 | 1 | 3 | 1 | 0 | 1 | 2 | 3 | 1 | 1 | 2 | 3 | 0 | 0 | 3 | 3 | 2 | 0 | 0 | 3 | 1 | 0 | 0 | 2 | 2 |
| биты | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 |
Уберем 0-символы и проделаем то же самое для 1:
| символы | 3 | 3 | 1 | 2 | 2 | 1 | 3 | 1 | 1 | 2 | 3 | 1 | 1 | 2 | 3 | 3 | 3 | 2 | 3 | 1 | 2 | 2 |
| биты | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
И разберемся с оставшимися 2 и 3:
| символы | 3 | 3 | 2 | 2 | 3 | 2 | 3 | 2 | 3 | 3 | 3 | 2 | 3 | 2 | 2 |
| биты | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 |
Ну вот и все: последовательность символов превратилась в последовательности бит! А именно: C3210, C227 и C157, для хранения которых достаточно 56 бит вместо исходных 64.
И вроде бы все хорошо, но кроме собственно позиций-битиков нужно где-то хранить и количества символов: 10, 7 и 7 в нашем примере. Проблема в том, что, вообще говоря, все символы потока могут оказаться равны, т.е. максимальное значение k каждого символа потенциально равно длине потока!
В данном случае каждый символ мог встретиться от 0 до 32 раз -- а это еще 15 с копейками бит для хранения. Гм, 56+16=72 и уже как-то совсем не радует по сравнению с исходными 64!
К счастью, на помощь приходит все тот же Треугольник Паскаля, а именно: количество всех возможных сочетаний потока длины S, состоящего из R различных символов равно CS-1R-1. Получается C313=4495, т.е. 12 с копейками бит.
Конечно, это только если каждый из всех возможных символов встретился хотя бы один раз. В общем случае количество возможных сочетаний будет CS+R-1R-1, и мы получим C353=6545 -- все те же 12 бит, только больше копеек.
Очевидно, для 32 символов с 4 возможными значениями мы все еще проигрываем исходному тексту: 56+13=69. Но с ростом длины потока отношение используемых бит к остальным стремительно уменьшается.
0 до 255.
Алгоритм Побайтного кодирования Треугольником Паскаля (Byte-level Pascal's Triangle coding) состоит из следующих основных этапов:
NN, заданной пользователем.
XOR).
bpt по нашим любимым файлам:
| .html | rnd.12 | rnd.24 | rnd.36 | rnd.48 | .doc | |
| orig | 88819 | 131072 | 131072 | 131072 | 131072 | 43520 |
| bpt32 | 81355 | 105962 | 145822 | 163074 | 168004 | 19702 |
| bpt64 | 71679 | 93406 | 129099 | 143309 | 146375 | 17299 |
| bpt128 | 66257 | 85434 | 119695 | 132682 | 134442 | 16011 |
| bpt256 | 63342 | 79797 | 114559 | 129604 | 133242 | 15069 |
| bpt512 | 61874 | 76413 | 111639 | 128956 | 134050 | 14667 |
| bpt1024 | 61290 | 74233 | 109617 | 127771 | 133099 | 14780 |
| bpt2048 | 61360 | 72600 | 107957 | 126420 | 132814 | 33225 |
| p | 62162 | 69328 | 104248 | 123579 | 130912 | 16149 |
Как можно видеть, для .html и .doc файлов реально показанные bpt результаты существенно превосходят теоретически возможный предел побайтного Арифметического кодирования! Для случайных же rnd.NN файлов результаты заметно хуже, что и неудивительно.
Конечно, хотелось бы напрямую сравнить степени сжатия bpt с их сpt аналогами, но не совсем понятно как правильно это сделать: суть в том, что не существует однозначно эквивалентного соответствия. Длина читаемого блока? Скорость работы? Объем используемой памяти? Параметры обсчитываемых треугольников? Каждый из перечисленных критериев имеет смысл в своем контексте!
Давайте просто сведем в одну таблицу наилучшие результаты обоих алгоритмов вместе с их теоретическими пределами:
| .html | rnd.12 | rnd.24 | rnd.36 | rnd.48 | .doc | |||||||
| best | p | best | p | best | p | best | p | best | p | best | p | |
| cpt | 88118 | 88816 | 69401 | 69351 | 104330 | 104271 | 123654 | 123600 | 130993 | 130934 | 18667 | 25793 |
| bpt | 61290 | 62162 | 72600 | 69328 | 107957 | 104248 | 126420 | 123579 | 132814 | 130912 | 14667 | 16149 |
Ну что тут скажешь, закономерность видна невооруженным глазом!
GMP. Дело в том, что на данный момент времени The GNU Multiple Precision Arithmetic Library является наиболее оптимальным выбором из свободно доступных вариантов, обеспечивающих максимально возможную производительность.
Но как это водится, не обошлось и без ложки дегтя: GMP по своему конструктиву всегда привязана к определенной модели процессора и требует сделать выбор в момент установки.
Внимание! Программы были собраны с использованием gmp-5.1.3, сконфигурированной для CPU=core2 и GMP_LIMB_BITS=32. Это в частности означает, что:
core2!
GMP, оптимизированной под ваш конкретный компьютер.
cptest.exe ВООБЩЕ не будет работать на старых процессорах, несовместимых с core2!
cptest cNN|d filename
cNN |
кодировать файл filename с параметром NN в файл filename.cptNN |
d |
декодировать файл filename.cptNN в файл filename.cptNN.orig |
filename |
имя файла |
Параметр NN означает использование путей длины n=2^NN при 3<=NN<=16 (от 8 до 65536 бит). NN=8 (256 бит) является вполне разумным началом.
Примеры использования:
cptest c8 some.doc
cptest d some.doc.cpt8
В процессе работы на экран выводятся данные по обрабатываемым путям и блокам. Теоретический предел побитового Арифметического кодирования идет последней строкой.
cptool.exe ВООБЩЕ не будет работать на старых процессорах, несовместимых с core2!
cptool showC n k dcptool showFile n filenamecptool showTrian n k d
showC |
показать количество сочетаний С(n, k, d) |
showFile |
показать файл filename в виде путей бит длины n |
showTrian |
показать Ограниченный Треугольник Паскаля с параметрами (n, k, d) |
Примеры использования:
cptool showC 1024 512 1024
cptool showFile 32 some.doc
cptool showTrian 32 14 4
Было ли вам, например, интересно с чего это вдруг "легко видеть, что C1024512 -- это всего лишь 1019 бит"? showC, она самая!
А как с точки зрения cpt выглядят реальные файлы? Положим, в some.doc встречаются следующие 32-битные пути:

и
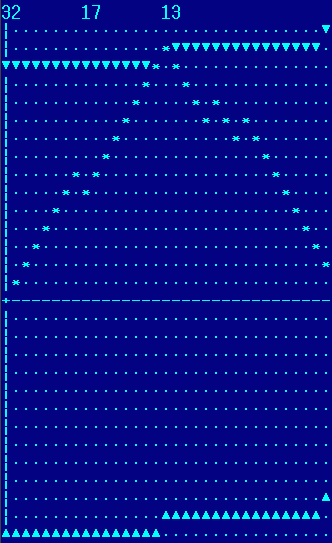
Тогда команды showTrian 32 14 4 и showTrian 32 17 13 покажут, как именно были рассчитаны 259625090 и 565721410 и нет ли здесь дополнительных резервов для улучшения.
Так, например, что будет, если последний путь (32, 17, 13) разбить на две части: до и после вершины? Окажется ли количество бит для хранения двух укороченных путей меньше, чем одного длинного? Всегда ли??
Параметры командной строки:
cptrm c|d filename
c |
кодировать файл filename в файл filename.trm |
d |
декодировать файл filename.trm в файл filename.trm.orig |
filename |
имя файла |
Суть работы программы заключается в замене каждого следующего байта файла на его отклонение от предыдущего. Для текстовых файлов, где идущие друг за другом буквы, скажем, принадлежат диапазону 'a'-'z', преобразование существенно уменьшает количество единиц в байтах.
Примеры использования:
cptrm c some.txt
cptrm d some.txt.trm
bptest.exe ВООБЩЕ не будет работать на старых процессорах, несовместимых с core2!
bptest cNN|d filename
cNN |
кодировать файл filename с параметром NN в файл filename.bptNN |
d |
декодировать файл filename.bptNN в файл filename.bptNN.orig |
filename |
имя файла |
Параметр NN означает использование блоков длины NN байт при 1<=NN<=8192. Значение 512 является вполне разумным началом.
Примеры использования:
bptest c512 some.doc
bptest d some.doc.bpt512
В процессе работы на экран выводятся данные по обрабатываемым путям и блокам. Теоретический предел побайтного Арифметического кодирования идет последней строкой.
Как ни странно, но исчерпывающего заключения не получится: далеко не все возможные идеи по улучшению уже были проверены; отсутствуют комментарии специалистов... В общем, дорога для Творчества все еще широко открыта!
Тем не менее, Алгоритм уже состоялся! Это самый важный итог.
Никакая часть данного материала не может быть использована в коммерческих целях без письменного разрешения автора.