К счастью, все может быть совсем не так -- выбор за вами!
Следующий ниже материал объясняет, чем является и чем не является многопоточное программирование, исследует вопросы производительности и масштабируемости, приводит примеры реальных программ, а также проливает свет на несколько довольно неожиданных особенностей C++.
Не знаю стоит ли отдельно упоминать, но статья развивает излагавшиеся в предыдущем материале Интерфейсы и Сообщения базовые принципы, так что если для вас это является новостью, то имеет смысл предварительно ознакомиться.
С уважением, Сергей Деревяго.
К сожалению, с точки зрения абсолютного большинства программистов и авторов (а порою и весьма уважаемых и компетентных в своей области авторов) MT -- это все то же самое обычное программирование, разве что щедро усыпанное невообразимым количеством mutex-ов "для корректности". В типичной настольной книжке вам приведут стандартный пример с двумя потоками (т.е. thread-ами), одновременно изменяющими значение одной и той же переменной, лихо вылечат ошибку посредством пресловутого mutex-а, а заодно и растолкуют что такое deadlock и почему много mutex-ов тоже плохо.
М-да... "И куды крестьянину податься?"
К счастью, не все так плохо: в природе встречаются авторы действительно понимающие MT. Авторы, стоявшие у истоков Стандарта POSIX Threads и умеющие доходчиво объяснять суть дела. Самой важной, классической книгой по теме, для нас безусловно является David R. Butenhof "Programming with POSIX Threads" -- вряд ли вы в полной мере постигнете C/C++ MT не прочитав данной книги. Ну а классический FAQ по теме -- это сообщения в ньюсгруппе comp.programming.threads того же автора. Скажем, если вам не вполне понятно использование некоторой функции и/или термина, то один из наиболее простых и эффективных способов -- это поиск сообщений автора Butenhof с заданным ключевым словом, например попробуйте: priority inversion group:comp.programming.threads author:Butenhof.
А теперь к делу. Итак, что же такое правильное MT приложение? Правильное MT приложение -- это прежде всего правильный дизайн! Вы никогда не сможете превратить серьезное однопоточное приложение в хорошее многопоточное приложение, сколько бы mutex-ов вы в него не добавили! Butenhof определяет его следующим образом: Multithreading is defined by an application design that ALLOWS FOR concurrent or simultaneous execution. Т.е.
Не удержусь и отмечу еще один архитектурный изъян многострадальной Java (и ее недалеких клонов), содержащей по mutex-у в каждом объекте и даже предоставляющей ключевое слово synchronized, позволяющее вам легко и удобно создавать методы, параллельное одновременное исполнение которых невозможно. Да-да, все именно так и есть, как оно выглядит: языки и технологии программирования зачастую проектируются технически некомпетентными в этой области специалистами!
"За что же досталось mutex-у?!" -- спросит меня опешивший читатель. "Неужели примитивы синхронизации вроде mutex-ов, semaphore-ов и т.п. вообще не нужны в MT приложениях?!" Ну, что же: они безусловно нужны для реализации некоторых, крайне низкоуровневых интерфейсов, но в обычном коде им просто нет места. Типичным примером правильного MT дизайна является приложение, в котором потоки извлекают из очереди сообщения для обработки и помещают в нее свои сообщения, обработка которых может быть произведена параллельно. Вот для реализации подобного рода очереди они и предназначены, а обычный код имеет дело только лишь с ее интерфейсом. К тому же, для случая ST приложения класс-реализация данного интерфейса никаких mutex-ов, очевидно, не должен использовать.
Судя по всему, идеальным MT приложением является приложение, в котором потоки вообще избегают какой бы то ни было синхронизации и, следовательно, могут исполняться без всяких взаимных задержек. На первый взгляд такая ситуация кажется абсурдной, но если в качестве некоего "логически единого" приложения представить себе два ST Web-сервера, работающих на двух разных машинах и отдающих пользователям один и тот же статический контент из собственных локальных копий, то мы имеем дело как раз с тем самым идеальным случаем, когда добавление второго, абсолютно независимого потока (факт. запуск на другой машине зеркального сервера) в буквальном смысле удваивает общую производительность комплекса, без оговорок.
Но в реальных MT приложениях потоки работают в кооперации друг с другом (и операционной системой, конечно же) и, следовательно, вынуждены синхронизировать свою работу. А синхронизация неизбежно приводит к задержкам, на время которых независимое одновременное исполнение приостанавливается. Так что количество и продолжительность промежутков синхронизации в правильно спроектированном MT приложении должна стремиться к относительному нулю, т.е. быть исчезающе малой по сравнению с общим временем работы потока.
Описанный выше дизайн потоки+очередь является классическим примером правильного MT приложения, если конечно потоки не пытаются передавать друг другу настолько малые подзадачи, что операция по помещению/извлечению сообщения из очереди занимает больше времени, чем обработка подзадачи самим потоком "на месте". Дизайн потоки+очередь мы и будем использовать в нашем учебном примере mtftext, равно как и в следующих за ним приложениях.
Прямым решением данной проблемы является повсеместное явное использование собственного распределителя памяти, кэширующего полученные от глобального распределителя блоки. Т.е. своего объекта mem_pool для каждого отдельного потока (как минимум). Конечно, с точки зрения удобства кодирования повсеместное мелькание ссылок mem_pool& трудно назвать приемлемым -- стоит ли овчинка выделки? Давайте разберемся с помощью следующего примера:
| example1/main.cpp |
|---|
#include <list>
#include <vector>
#include <stdio.h>
#include <time.h>
#include <ders/stl_alloc.hpp>
#include <ders/thread.hpp>
using namespace std;
using namespace ders;
const int N=1000;
const int M=10000;
void start_std(void*)
{
list<int> lst;
for (int i=0; i<N; i++) {
for (int j=0; j<M; j++) lst.push_back(j);
for (int j=0; j<M; j++) lst.pop_front();
}
}
void start_ders(void*)
{
mem_pool mp;
stl_allocator<int> alloc(mp);
list<int, stl_allocator<int> > lst(alloc);
for (int i=0; i<N; i++) {
for (int j=0; j<M; j++) lst.push_back(j);
for (int j=0; j<M; j++) lst.pop_front();
}
}
int main(int argc, char** argv)
{
if (argc!=3) {
m1:
fprintf(stderr, "main num_threads std|ders");
return 1;
}
int numThr=atoi(argv[1]);
if ( !(numThr>=1 && numThr<=100) ) {
fprintf(stderr, "num_threads must be in [1, 100]");
return 1;
}
void (*start)(void*);
if (strcmp(argv[2], "std")==0) start=start_std;
else if (strcmp(argv[2], "ders")==0) start=start_ders;
else goto m1;
clock_t c1=clock();
mem_pool mp;
vector<sh_thread> vthr;
for (int i=0; i<numThr; i++) vthr.push_back(new_thread(mp, start, 0));
for (int i=0; i<numThr; i++) vthr[i]->join();
clock_t c2=clock();
printf("%d\t%d\t%s\n", numThr, int(c2-c1), argv[2]);
return 0;
}
|
Программа запускает заданное в командной строке количество потоков и в каждом из них выполнят фиксированное количество вставок/удалений элементов в стандартный список. Отличие функции start_ders состоит в том, что вместо стандартного аллокатора по умолчанию lst использует аллокатор на основе mem_pool.
| 1 CPU | ||||||||
| numThr | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| std | 13.913 | 28.01 | 43.255 | 62.984 | 85.696 | 107.184 | 128.758 | 155.022 |
| ders | 0.507 | 1.011 | 1.512 | 2.022 | 2.533 | 3.054 | 3.562 | 4.068 |
| std/ders | 27.4 | 27.7 | 28.6 | 31.1 | 33.8 | 35.1 | 36.1 | 38.1 |
| 1 CPU, Hyper-Threading | ||||||||
| numThr | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| std | 60.057 | 135.573 | 211.156 | 278.135 | 350.625 | 415.437 | 489.187 | 558.109 |
| ders | 1.182 | 3.322 | 4.968 | 6.635 | 8.242 | 10.020 | 11.661 | 13.239 |
| std/ders | 50.8 | 40.8 | 42.5 | 41.9 | 42.5 | 41.5 | 42.0 | 42.1 |
| 2 CPU, SMP | ||||||||
| numThr | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| std | 20.385 | 129.032 | 206.760 | 256.699 | 333.670 | 384.449 | 455.674 | 519.002 |
| ders | 0.396 | 0.406 | 0.609 | 0.812 | 1.014 | 1.218 | 1.455 | 1.614 |
| std/ders | 51.5 | 317.8 | 339.5 | 316.1 | 329.1 | 315.6 | 313.2 | 321.6 |
| 2 CPU, Hyper-Threading | ||||||||
| numThr | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| std | 3.286 | 24.679 | 37.496 | 52.798 | 66.961 | 80.461 | 95.084 | 109.309 |
| ders | 0.580 | 0.582 | 1.468 | 1.472 | 1.900 | 2.257 | 2.628 | 2.953 |
| std/ders | 5.7 | 42.4 | 25.5 | 35.9 | 35.2 | 35.6 | 36.2 | 37.0 |
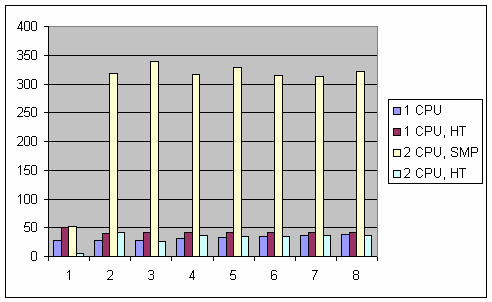
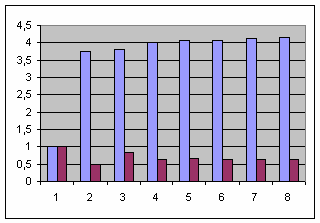
Время работы указано в секундах, а в строке std/ders приведено отношение времени работы функций -- именно те данные, которые нас и интересуют. Следующая ниже диаграмма показывает их в более наглядной форме:
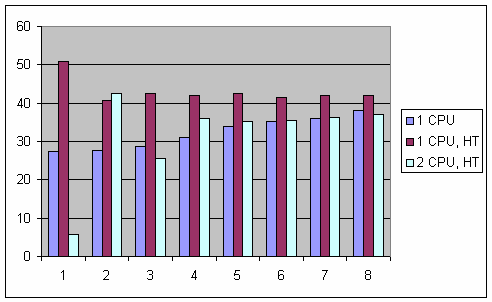
Удивительно, но факт: относительный выигрыш 2 CPU, SMP компьютера настолько велик, что даже имеет смысл привести ту же самую диаграмму без его участия:
Проведем краткий анализ:
start_ders, использующая аллокатор на основе mem_pool работает в десятки и даже сотни (!!!) раз быстрее. Так что "повсеместное мелькание" mem_pool& является, мягко говоря, оправданным. И даже более того! Учитывая ТАКУЮ разницу эффективности, вопрос должен ставиться совершенно иначе:
В нашем случае каждый запущенный поток должен выполнить один и тот же объем работы, т.е. при отсутствии параллелизма (напр. когда приложению доступен только один процессор) общее время работы приложения будет увеличиваться (не менее чем) прямо пропорционально количеству рабочих потоков, задаваемых параметром numThr. С другой стороны, в случае идеального параллелизма, время работы приложения должно уменьшиться в количество раз, равное количеству задействованных процессоров.
Разобраться с масштабируемостью нам поможет следующая таблица. Значения в ячейках рассчитаны по формуле t(N)/t(1)/N. Т.е. время работы приложения с количеством рабочих потоков равным N делится на время, затраченное одним потоком, а затем на количество потоков. Тем самым мы измеряем относительное отклонение времени работы нашего MT приложения от обычного однопоточного варианта (факт. ST приложения).
| numThr | |||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ||
| 1 CPU | std | 1.000 | 1.007 | 1.036 | 1.132 | 1.232 | 1.284 | 1.322 | 1.393 |
| ders | 1.000 | 0.997 | 0.994 | 0.997 | 0.999 | 1.004 | 1.004 | 1.003 | |
| 1 CPU, HT | std | 1.000 | 1.129 | 1.172 | 1.158 | 1.168 | 1.153 | 1.164 | 1.162 |
| ders | 1.000 | 1.405 | 1.401 | 1.403 | 1.395 | 1.413 | 1.409 | 1.400 | |
| 2 CPU, SMP | std | 1.000 | 3.165 | 3.381 | 3.148 | 3.274 | 3.143 | 3.193 | 3.182 |
| ders | 1.000 | 0.513 | 0.513 | 0.513 | 0.512 | 0.513 | 0.525 | 0.509 | |
| 2 CPU, HT | std | 1.000 | 3.755 | 3.804 | 4.017 | 4.076 | 4.081 | 4.134 | 4.158 |
| ders | 1.000 | 0.502 | 0.844 | 0.634 | 0.655 | 0.649 | 0.647 | 0.636 | |
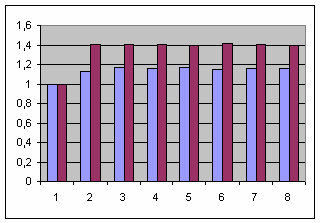
Ну а выглядят данные следующим образом:
| 1 CPU | 1 CPU, HT | 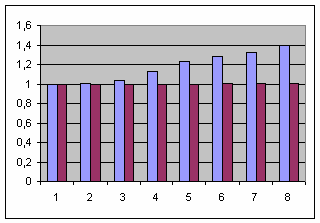 |
 |
| 2 CPU, SMP | 2 CPU, HT | 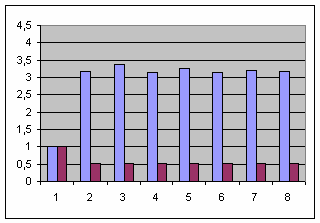 |
 |
Как можно видеть,
start_ders демонстрирует практически идеальное соответствие эталонному однопоточному варианту, т.е. присутствующие механизмы синхронизации не вызывают заметных накладных расходов. С другой стороны, накладные расходы функции start_std практически линейно увеличиваются с ростом количества задействованных потоков, достигая в итоге значения 1.4.
start_std увеличиваются до трех задействованных потоков, а затем стабилизируются возле значения 1.2. Накладные расходы функции start_ders стабилизируются уже на двух потоках, но на более высоком значении 1.4. Т.е. в этом случае несмотря на заметно более высокую скорость работы (42 раза, т.е. 4200%), масштабируемость start_ders примерно на 17% хуже start_std, т.е.
start_std демонстрирует более-менее стабильную масштабируемость около значения 3,2 раза. При этом значения нечетного количества потоков чуть больше, а четных -- чуть меньше данной величины (вероятно, худшая масштабируемость нечетного количества потоков связана с необходимостью планирования их работы на четном количестве процессоров). С другой стороны, функция start_ders показывает практически идеальные 0,5+дельта, т.е. удвоение количества процессоров в два раза уменьшило затрачиваемое на работу время.
start_ders и меньше единицы, но демонстрируемый в среднем результат 0,65 заметно хуже предыдущего варианта и уж точно никак не похож на 0,25, которого можно было бы ожидать от полноценного 4 CPU, SMP компьютера.
start_ders на 2 CPU, SMP и 4 CPU, SMP составляет 0,5 и 0,25 соответственно. Следующая ниже таблица показывает насколько ожидаемая масштабируемость отличается от реальной:
| numThr | |||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| 1 CPU | 0.997 | 0.994 | 0.997 | 0.999 | 1.004 | 1.004 | 1.003 |
| 1 CPU, HT | 2.810 | 2.802 | 2.806 | 2.790 | 2.826 | 2.818 | 2.800 |
| 2 CPU, SMP | 1.026 | 1.026 | 1.026 | 1.024 | 1.026 | 1.050 | 1.018 |
| 2 CPU, HT | 2.008 | 3.376 | 2.536 | 2.620 | 2.596 | 2.588 | 2.544 |
Увы, все очень печально: масштабируемость HT вариантов приблизительно в 2,6-2,8 раз хуже ожидаемой. Данная цифра тем более любопытна, что даже если считать один HT процессор не за два, а один CPU, то полученные значения 1,3-1,4 все равно больше единицы, т.е.
Или все же покажет?!
Как известно, стандартные потоки ввода/вывода C++ работают существенно медленнее потоков ввода/вывода C. Но, к сожалению, даже C-шные потоки FILE не подходят для MT приложений, т.к. все операции над ними обязаны быть thread-safe по умолчанию, а быстрые варианты функций getc() и putc(), не использующие пресловутые mutex-ы, имеют другие имена: getc_unlocked() и putc_unlocked() соответственно. Тем самым, написание кода, одинаково хорошо работающего как в ST, так и в MT окружении становится невозможным.
Главным образом, для решения этой проблемы и был создан класс file, не использующий блокировок:
| example2/main.cpp |
|---|
#include <memory>
#include <vector>
#include <stdio.h>
#include <time.h>
#include <ders/file.hpp>
#include <ders/text_buf.hpp>
#include <ders/thread.hpp>
using namespace std;
using namespace ders;
const int BUF_SIZE=64*1024;
struct MainData {
const char* fname;
MainData(const char* fn) : fname(fn) {}
};
struct ThreadData {
MainData* md;
int n;
ThreadData(MainData* md_, int n_) : md(md_), n(n_) {}
};
void start_std(void* arg)
{
ThreadData* td=(ThreadData*)arg;
auto_ptr<ThreadData> guard(td);
mem_pool mp;
file err(mp, fd::err);
FILE* fin=fopen(td->md->fname, "rb");
if (!fin) {
err.write(text_buf(mp)+"Can't open "+td->md->fname+'\n');
return;
}
sh_text oname=text_buf(mp)+td->md->fname+'.'+td->n;
FILE* fout=fopen(oname->c_str(), "wb");
if (!fout) {
err.write(text_buf(mp)+"Can't create "+oname+'\n');
fclose(fin);
return;
}
setvbuf(fin, 0, _IOFBF, BUF_SIZE);
setvbuf(fout, 0, _IOFBF, BUF_SIZE);
for (int ch; (ch=fgetc(fin))!=EOF; )
fputc(ch, fout);
fclose(fout);
fclose(fin);
}
void start_ders(void* arg)
{
ThreadData* td=(ThreadData*)arg;
auto_ptr<ThreadData> guard(td);
mem_pool mp;
file err(mp, fd::err);
file fin(mp);
if (!fin.open(td->md->fname, file::rdo, 0)) {
err.write(text_buf(mp)+"Can't open "+td->md->fname+'\n');
return;
}
sh_text oname=text_buf(mp)+td->md->fname+'.'+td->n;
file fout(mp);
if (!fout.open(oname, file::wro, file::crt|file::trnc)) {
err.write(text_buf(mp)+"Can't create "+oname+'\n');
return;
}
buf_reader br(mp, fin, BUF_SIZE);
buf_writer bw(mp, fout, BUF_SIZE);
for (int ch; (ch=br.read())!=-1; )
bw.write(ch);
}
int main(int argc, char** argv)
{
mem_pool mp;
file err(mp, fd::err);
file out(mp, fd::out);
if (argc!=4) {
m1:
err.write("main file num_threads std|ders");
return 1;
}
int numThr=atoi(argv[2]);
if ( !(numThr>=1 && numThr<=100) ) {
err.write("num_threads must be in [1, 100]");
return 1;
}
void (*start)(void*);
if (strcmp(argv[3], "std")==0) start=start_std;
else if (strcmp(argv[3], "ders")==0) start=start_ders;
else goto m1;
MainData md(argv[1]);
clock_t c1=clock();
vector<sh_thread> vthr;
for (int i=0; i<numThr; i++)
vthr.push_back(new_thread(mp, start, new ThreadData(&md, i)));
for (int i=0; i<numThr; i++) vthr[i]->join();
clock_t c2=clock();
out.write(text_buf(mp)+numThr+'\t'+int(c2-c1)+'\t'+argv[3]+'\n');
return 0;
}
|
Пример запускает заданное количество потоков, в каждом из которых создается копия указанного в командной строке файла посредством выбранной функции: start_std() или start_ders(). Потоками используется посимвольное копирование через буфер размера BUF_SIZE.
В таблице представлены усредненные результаты запуска (в секундах) на трех разных компиляторах с файлом десятимегабайтного размера:
| 1 CPU | ||||||||||
| numThr | 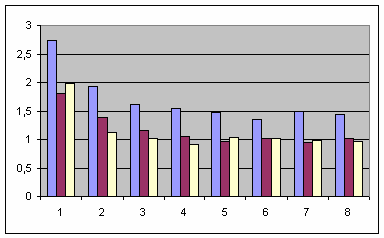 |
|||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |||
| 1 | std | 2.02 | 3.98 | 5.91 | 7.94 | 9.85 | 11.89 | 14.00 | 15.81 | |
| ders | 0.74 | 2.06 | 3.64 | 5.14 | 6.72 | 8.81 | 9.40 | 10.96 | ||
| std/ders | 2.73 | 1.93 | 1.62 | 1.54 | 1.47 | 1.35 | 1.49 | 1.44 | ||
| 2 | std | 1.45 | 2.74 | 4.29 | 5.75 | 7.01 | 8.53 | 9.82 | 11.25 | |
| ders | 0.80 | 1.98 | 3.72 | 5.40 | 7.24 | 8.41 | 10.41 | 11.19 | ||
| std/ders | 1.81 | 1.38 | 1.15 | 1.06 | 0.97 | 1.01 | 0.94 | 1.01 | ||
| 3 | std | 1.03 | 2.16 | 3.67 | 5.10 | 7.20 | 8.01 | 9.55 | 10.55 | |
| ders | 0.52 | 1.93 | 3.59 | 5.59 | 6.92 | 7.86 | 9.68 | 10.88 | ||
| std/ders | 1.98 | 1.12 | 1.02 | 0.91 | 1.04 | 1.02 | 0.99 | 0.97 | ||
| 2 CPU, SMP | ||||||||||
| numThr | 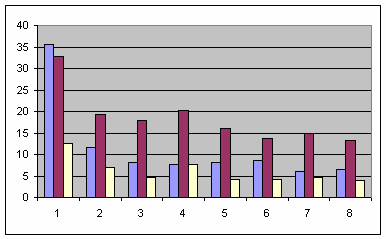 |
|||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |||
| 1 | std | 2.13 | 4.53 | 5.35 | 7.67 | 8.79 | 10.46 | 10.59 | 11.76 | |
| ders | 0.06 | 0.39 | 0.65 | 0.99 | 1.09 | 1.22 | 1.77 | 1.81 | ||
| std/ders | 35.50 | 11.62 | 8.23 | 7.75 | 8.06 | 8.57 | 5.98 | 6.50 | ||
| 2 | std | 1.97 | 7.36 | 11.82 | 14.39 | 17.76 | 20.64 | 22.44 | 25.77 | |
| ders | 0.06 | 0.38 | 0.66 | 0.71 | 1.11 | 1.51 | 1.50 | 1.93 | ||
| std/ders | 32.83 | 19.37 | 17.91 | 20.27 | 16.00 | 13.67 | 14.96 | 13.35 | ||
| 3 | std | 1.75 | 2.35 | 4.36 | 4.94 | 5.39 | 6.19 | 6.97 | 8.14 | |
| ders | 0.14 | 0.34 | 0.96 | 0.64 | 1.29 | 1.47 | 1.48 | 2.08 | ||
| std/ders | 12.50 | 6.91 | 4.54 | 7.72 | 4.18 | 4.21 | 4.71 | 3.91 | ||
Как можно видеть,
start_ders работает быстрее в 1.4-2.7, 0.9-1.8 и 0.9-2.0 раз для каждого из трех компиляторов соответственно. Вероятно, значения меньше 1.0 (т.е. небольшое замедление, а не ускорение работы) являются следствием ошибок измерения, неизменно возникающих при замерах времени работы приложений, интенсивно работающих с файловой подсистемой.
start_ders, так скажем, более очевидно: в 6.0-35.5, 13.4-32.9 и 4.2-12.5 раз соответственно!
getc() и putc() полностью невостребована. А по ходу увеличения количества рабочих потоков выигрыш постепенно уменьшается в силу того, что узким местом масштабируемости является сама файловая подсистема, не поддерживающая эффективного распараллеливания запросов ввода/вывода в силу своего устройства.
Таким образом,
ders::file способно ускорить выполнение MT приложений в десятки раз!
И, в свете всего вышеперечисленного, у нас есть вполне определенный ответ на вопрос "Оправдано ли создание своих собственных классов, предоставляющих альтернативную реализацию давным-давно известных стандартных функций ввода/вывода?": увы, "не мона, а нуна"!
Более того, согласно замыслу прикладной код ничего не должен знать о количестве одновременно работающих потоков, да и вообще каким бы то ни было образом ссылаться на объекты типа mutex и thread.
Основная идея состоит в том, что общая задача приложения разбивается на подзадачи, которые могут быть выполнены параллельно: тем самым мы разрешаем параллельное одновременное выполнение, но ни в коем случае его не требуем! На первый взгляд фраза о том, что мы не требуем параллельного выполнения может показаться избыточной, но это не так. Она имеет вполне определенный смысл, и он заключается в том, что отсутствие параллельно работающих потоков не приведет к остановке всего приложения, как это неизбежно происходит в стандартном примере производитель/потребитель с ограниченным буфером, когда отсутствие одного из них означает бесконечное ожидание оставшегося.
Учебной задачей является все тот же поиск текста в файлах, но только многопоточный. Таким образом, суть задачи сводится к выполнению следующих операций:
Операции 2 и 3, очевидно, можно выполнять параллельно операции 1, а сам алгоритм, при этом, будет выглядеть следующим образом:
FindFiles, содержащее имя корневой директории поиска.
FindFiles -- обрабатываем директорию, порождая сообщения FindFiles и ScanFile.
ScanFile -- обрабатываем файл, выводя найденные строки.
А теперь самое время заглянуть в исходный код:
/** @file
* Main file of mtftext program.
*/
#include <vector>
#include <stdlib.h>
#include <ders/dir.hpp>
#include <ders/file.hpp>
#include <ders/text_buf.hpp>
#include <ders/thread_pool.hpp>
#include <ders/wldcrd_mtchr.hpp>
#include "msg.hpp"
namespace mtftext { // ::mtftext
Весь исходный код, кроме функции main(), естественно, заключен в namespace, совпадающий с именем программы.
using namespace ders;
struct CmdLineParser {
Для разбора аргументов командной строки используется специальная структура, чьи поля приближены к именам соответствующих параметров. Следующая ниже структура MainTask содержит, в принципе, те же самые данные, но их именование отражает их смысл использования, а не видимый пользователю интерфейс командной строки.
bool isS;
int numThr;
sh_text word;
sh_text mask;
CmdLineParser(mem_pool& mp) : isS(false), numThr(0), word(nt(mp)), mask(
nt(mp)) {}
void parse(int argc, char** argv);
};
struct MainTask : public task {
Главная структура программы, параллельно выполняющая свою функцию proc() с помощью класса ders::thread_pool.
bool exitOnErr;
sh_text srchPatt;
wldcrd_mtchr fileMchr;
MainTask(bool eoe, sh_text sp, sh_text mk) : exitOnErr(eoe),
srchPatt(sp), fileMchr(sp.pool(), mk) {}
virtual void destroy(mem_pool& mp2) { destroy_this(this, mp2); }
Типичная реализация чистой виртуальной функции destroy, косвенно унаследованной от интерфейса ders::destroyable.
virtual void proc(mem_pool& mp, const dq_vec& dqv, void* arg, task_opers&
to);
void doFindFiles(mem_pool& mp, data_queue& dq, const FindFilesMsg& msg);
void doScanFile(mem_pool& mp, data_queue& dq, const ScanFileMsg& msg);
};
void CmdLineParser::parse(int, char** argv)
{
const char* usage="mtftext [-s] num_threads word mask";
Командная строка имеет необязательный параметр -s (stop), предписывающий сразу же завершать работу при обнаружении ошибок. По умолчанию же в stderr записывается сообщение об ошибке и работа продолжается.
mem_pool& mp=word.pool(); char** it=argv; if (!*++it) throw newExitMsgException(mp, _FLINE_, usage, 1);Возбуждаем исключение
ExitMsgException в случае ошибки, которое используется для выхода из программы с заданным кодом возврата и, возможно, текстом сообщения. Похожего результата можно добиться и с помощью пары fprintf()/exit(), но в этом случае не будут вызваны деструкторы локальных объектов, что, вообще говоря, неприемлемо.
if (*it==ch_rng("-s")) {
isS=true;
if (!*++it) throw newExitMsgException(mp, _FLINE_, usage, 1);
}
numThr=atoi(*it);
if ( !(numThr>=1 && numThr<=100) ) {
throw newExitMsgException(mp, _FLINE_, "num_threads must be in [1, 100]",
1);
Проверяем заданное пользователем количество потоков на соответствие разумным рамкам.
}
if (!*++it) throw newExitMsgException(mp, _FLINE_, usage, 1);
*word=*it;
if (!*++it) throw newExitMsgException(mp, _FLINE_, usage, 1);
*mask=*it;
if (*++it) throw newExitMsgException(mp, _FLINE_, usage, 1);
}
void MainTask::proc(mem_pool& mp, const dq_vec& dqv, void*, task_opers&)
{
data_queue& dq=*dqv[0];
for (;;) {
Этот объемлющий цикл вокруг цикла обработки сообщений встречается только в программе mtftext, т.к. только в ней у пользователя есть возможность не прерывать работу в случае обнаружения ошибок.
shException exc(mp, 0);
try {
for (MsgIO mio(mp, dq); ; ) {
sh_ptr<Msg> msg=mio.read();
if (!msg.get()) break;
Отсутствие прочитанного сообщения может означать как исчерпание всех сообщений, так и is_intr() состояние очереди.
switch (msg->getType()) {
case Msg::FindFiles: {
doFindFiles(mp, dq, msg->to<FindFilesMsg>());
break;
}
case Msg::ScanFile: {
doScanFile(mp, dq, msg->to<ScanFileMsg>());
break;
}
}
}
return;
}
catch (shException she) { exc=she; }
catch (...) { exc=recatchException(mp, _FLINE_); }
На корректно работающих компиляторах для обработки исключения вполне достаточно единственного блока catch (...) { recatchException() }, что сильно упрощает программирование, но, к сожалению, реальный мир требует жертвовать изящностью кода ради возможности использования важных промышленных компиляторов.
file(mp, fd::err).write(text_buf(toTextAll(exc))+'\n');Используем объект
text_buf для удобного объединения строки и символа.
if (exitOnErr) {
dq.set_intr(true);
break;
}
}
}
void MainTask::doFindFiles(mem_pool& mp, data_queue& dq, const FindFilesMsg&
msg)
{
MsgIO mio(mp, dq);
sh_dir shd=new_dir(mp, msg.dirName);
for (dir::entry dent(mp); shd->find_next(dent); ) {
if (dent.name=="." || dent.name=="..")
continue;
sh_text fname=shd->full_name(dent);
if (dent.isdir) {
FindFilesMsg m(fname);
mio.write(m);
continue;
}
if (fileMchr.match(dent.name)) {
ScanFileMsg m(fname);
mio.write(m);
}
}
}
void MainTask::doScanFile(mem_pool& mp, data_queue&, const ScanFileMsg& msg)
{
file out(mp, fd::out);
Создаем файл для вывода, привязанный к дескриптору stdout.
file fin(mp, msg.fileName, file::rdo, 0);
buf_reader br(mp, fin, 64*1024);
sh_text line(nt(mp));
for (int num=1; br.read_line(line); num++) {
if (line->find(srchPatt)!=line->end())
out.write(text_buf(mp)+msg.fileName+':'+num+':'+line+'\n');
}
}
} // namespace ::mtftext
int main(int argc, char** argv)
{
using namespace ders;
using namespace mtftext;
mem_pool mp;
file err(mp, fd::err);
file out(mp, fd::out);
shException exc(mp, 0);
try {
CmdLineParser clp(mp);
clp.parse(argc, argv);
MainTask mt(clp.isS, clp.word, clp.mask);
sh_data_queue dq=new_data_queue(mp);
MsgIO mio(mp, *dq);
FindFilesMsg m(nt(mp, ""));
mio.write(m);
Записываем в очередь первое сообщение, предписывающее искать файлы в текущей директории.
sh_thread_pool tp=(clp.numThr>1) ? new_thread_pool(mp, clp.numThr-1) :
new_thread_pool(mp);
Создаем thread_pool с указанным пользователем количеством рабочих потоков: если numThr равен одному, то никаких потоков создавать не требуется и для работы используется специальная однопоточная реализация thread_pool интерфейса.
Специально отмечу, что возможность однопоточной отладки логики работы многопоточных приложений трудно переоценить! Благодаря существованию отдельной однопоточной реализации thread_pool, практически вся разработка может проходить в комфортной и предсказуемой однопоточной среде!
tp->exec(mt, dq_vec(1, dq.get()));Запускаем одновременное выполнение функции
MainTask::proc() всеми потоками thread_pool-а + вызвавшим exec() потоком функции main(). Именно поэтому в new_thread_pool() передается значение numThr-1.
return (dq->is_intr()) ? 2 : 0;Проверяем состояние очереди для определения причины окончания обработки и передаем ОС соответствующий код возврата.
}
catch (shException she) { exc=she; }
catch (...) { exc=recatchException(mp, _FLINE_); }
ExitMsgException* em=exc->is<ExitMsgException>();
if (em) {
if (em->message->size())
(em->exitCode ? err : out).write(text_buf(em->message)+'\n');
return em->exitCode;
}
Типичный блок обработки исключения ExitMsgException.
err.write(text_buf(toTextAll(exc))+'\n'); return 2; }
Параметры командной строки:
mtcksrc [-nt2] d|u mask[,mask2...]
[-ntN] |
количество потоков, 2 по умолчанию |
d |
проверять на соответствие DOS формату |
u |
проверять на соответствие UNIX формату |
mask[,mask2...] |
маски для поиска файлов, могут содержать * и ? символы |
Примеры использования:
mtcksrc.exe u *.h,*.hpp,*.c,*.cpp
mtcksrc.exe -nt1 d *.?pp
Несмотря на реальную полезность, текст программы практически не отличается от учебного примера mtftext. Единственное заметное отличие состоит в том, что сообщения о несоответствующих критериям строках не выводятся сразу же на экран, а собираются в один буфер для единовременного вывода в конце функции:
void MainTask::doCheckFile(mem_pool& mp, data_queue&, const CheckFileMsg& msg)
{
text_buf tout(mp);
file fin(mp, msg.fileName, file::rdo, 0);
buf_reader br(mp, fin, 64*1024);
sh_text line(nt(mp));
for (int num=1; br.read_line(line, false); num++) {
assert(line->size()>0);
if (line->back()=='\n') {
if (line->ends("\r\n")) {
if (!dos) tout+msg.fileName+':'+num+":dos\n";
line->uninitialized_resize(line->size()-2);
}
else {
if (dos) tout+msg.fileName+':'+num+":unix\n";
line->uninitialized_resize(line->size()-1);
}
}
if (line->find('\t')!=line->end()) tout+msg.fileName+':'+num+":tab\n";
if (line->size()>80) tout+msg.fileName+':'+num+":long "+line->size()+'\n';
if (line->size()>0 && line->back()==' ')
tout+msg.fileName+':'+num+":ending space\n";
}
if (tout.size()) file(mp, fd::out).write(tout);
}
В силу того, что файлы обрабатываются несколькими потоками одновременно, одновременно и независимо обнаруживаются и подходящие условиям строки, так что вывод их на экран без предварительного объединения в один, соответствующий всему файлу фрагмент, неудобен для пользователя. Если же необходимо получать упорядоченную не только по строкам, но и по файлам информацию (что очень полезно при первой проверке неряшливо написанного кода), то можно воспользоваться ключом -nt1, предписывающим однопоточную работу.
Ну, а теперь самое время проверить ваши собственные программы -- из-за пресловутого Copy/Paste DOS фрагменты не так уж и редко встречаются в UNIX файлах...
Параметры командной строки:
mtdel [-nt2] mask[,mask2...]
[-ntN] |
количество потоков, 2 по умолчанию |
mask[,mask2...] |
маски для поиска файлов, могут содержать * и ? символы |
Примеры использования:
mtdel.exe *.obj,*.exe,*.res,out.???\*
mtdel.exe -nt1 *.bak
Ну а эта программа, несмотря на кажущуюся простоту постановки задачи, является дальнейшим усложнением предыдущего примера. В процессе ее работы решаются следующие дополнительные задачи:
К несчастью, решение данной простой задачи не вызовет никакого труда даже у едва знакомого с многопоточным программированием кодировщика: всего-то и нужно, что создать один глобальный счетчик, да защитить его mutex-ом!
С другой стороны, толковым программистам уже известно чем чреваты глобальные объекты, защищенные mutex-ами, а некоторые даже знают о том, что грамотный MT дизайн категорически не приветствует подобного рода решений!
Концептуально правильное решение проблемы получения итоговой статистики состоит в том, что каждый из рабочих потоков ведет свою собственную личную статистику, которую он может изменять абсолютно независимо и параллельно. А итоговая статистика получается в конце работы программы путем сложения их всех -- и никаких тебе mutex-ов!
Для создания личных аргументов потока предназначена функция MainTask::proc_arg(). Она вызывается thread_pool-ом для получения указателей, которые им будут переданы как arg в MainTask::proc(). Функция MainTask::proc_arg() сохраняет созданные объекты в списке, который затем обрабатывается MainTask::getStat() для получения итоговой статистики.
Отмечу, что для хранения Stat аргументов потоков специально используется список list<Stat>, а не более привычный vector<Stat>. Дело в том, что в процессе добавления элементов в вектор используемая им память неоднократно перераспределяется, так что указатели на объекты Stat, ранее возвращенные функцией MainTask::proc_arg() инвалидируются. А воспользоваться вызовом vector::reserve() мы не можем в силу того, что MainTask ничего не должна знать о количестве рабочих потоков.
А вот еще одна серьезная задача, когда пресловутого mutex-а, казалось бы, уж точно не избежать! Суть проблемы в том, что если сразу же выводить на экран возникающие в процессе работы ошибки, то они вполне могут затеряться в выводе других потоков, продолжающих обработку своих сообщений. Решением задачи является запись сообщения об ошибке в специальный глобальный буфер, чтобы после окончания работы MainTask::proc() функция main() смогла его вывести последним.
В этом случае действительно имеет смысл завести общий для всех потоков буфер MainTask::gerr, распределенный с помощью глобального пула MainTask::gmp, и разграничить к нему доступ посредством привычной блокировки. Мы, конечно, могли бы завести по буферу в каждом аргументе потока и объединить их в конце работы точно так же, как мы объединяем статистику, но в данном случае усложнение кода программы неоправданно, т.к. потокам не нужно постоянно обращаться к этим данным и никаких дополнительных накладных расходов из-за данной блокировки не возникает.
Как ни крути, но очевидное решение с mutex-ом напрашивается само-собой и избежать его нам поможет только наблюдение о том, что однопоточный вариант работы программы ни в каких mutex-ах не нуждается, и даже более того: у нас должна быть возможность слинковать его с обычными, однопоточными версиями библиотек, никаких ссылок на mutex-ы, очевидно, не приемлющих. Так что прямое использование mutex-а отпадает... Как же быть?
К счастью, решение есть и оно заключается в использовании интерфейса task_opers, передаваемого в виде аргумента to в функцию MainTask::proc() thread_pool-ом. Он предоставляет функцию invoke(), которая позволяет вызывать переданный указатель на функцию с применением необходимой блокировки, т.е. необходимый (или нежелательный!) mutex автоматически обеспечивается самим thread_pool-ом:
void MainTask::proc(mem_pool& mp, const dq_vec& dqv, void* arg, task_opers& to)
{
data_queue& dq=*dqv[0];
Stat& st=*static_cast<Stat*>(arg);
приводим аргумент потока к его настоящему типу Stat
for (;;) {
shException exc(mp, 0);
try {
for (MsgIO mio(mp, dq); ; ) {
sh_ptr<Msg> msg=mio.read();
if (!msg.get()) break;
switch (msg->getType()) {
case Msg::FindFiles: {
doFindFiles(mp, dq, st, msg->to<FindFilesMsg>());
break;
}
}
}
return;
}
catch (shException she) { exc=she; }
catch (...) { exc=recatchException(mp, _FLINE_); }
ErrData ed(gerr, toTextAll(exc));
to.invoke(addError, &ed);
заполняем ErrData и вызываем функцию addError() для добавления сообщения об ошибке
dq.set_intr(true);
break;
}
}
Параметры командной строки:
mtcnvsrc [-nt2] [d|u][e] mask[,mask2...]
[-ntN] |
количество потоков, 2 по умолчанию |
[d] |
конвертировать в DOS формат |
[e] |
удалять пробелы в конце строки |
[u] |
конвертировать в UNIX формат |
mask[,mask2...] |
маски для поиска файлов, могут содержать * и ? символы |
Примеры использования:
mtcnvsrc.exe ue *.h,*.hpp,*.c,*.cpp
mtcnvsrc.exe -nt4 e *.?pp
Как можно видеть, прямым назначением программы является исправление ошибок, найденных mtcksrc. При этом, автоматически исправляется только то, что не требует человеческого вмешательства.
Ну а если говорить о сложности, то данная программа скорее является небольшим подготовительным этапом перед следующей, чем усложнением предыдущей. Единственный момент, на который можно обратить внимание -- это аргумент потока в виде более общей структуры Arg. На этот раз аргументы хранятся в векторе vector<sh_ptr<Arg> >, но это не приводит к описанным выше проблемам, т.к. в процессе их создания копируются и перераспределяются элементы sh_ptr<Arg>, а не сами тяжеловесные Arg структуры.
Параметры командной строки:
mtdirdiff [-nt2] old_dir new_dir diff_dir
[-ntN] |
количество потоков, 2 по умолчанию |
old_dir |
директория со старыми файлами |
new_dir |
директория с новыми файлами |
diff_dir |
директория для копирования изменений в виде add, del и mod поддиректорий |
Примеры использования:
mtdirdiff.exe src\mtprog.sav src\mtprog src\mtprog.diff
А здесь мы уже имеем дело с небольшой, но достаточно нетривиальной многопоточной программой, в процессе создания которой решалось несколько неочевидных задач проектирования.
thread_pool::exec() вызывается неоднократно:
sh_thread_pool tp=(clp.numThr>1) ? new_thread_pool(mp, clp.numThr-1) :
new_thread_pool(mp);
MainTask mt(clp.oldDir, clp.newDir, clp.diffDir);
sh_data_queue dq=new_data_queue(mp);
dq_vec dqv(1, dq.get());
MsgIO mio(mp, *dq);
{
FindFilesMsg m1(&mt.oldDir), m2(&mt.newDir);
mio.write(m1);
mio.write(m2);
}
tp->exec(mt, dqv);
{
CompareMsg m1(true), m2(false);
mio.write(m1);
mio.write(m2);
}
mt.argno=0;
tp->exec(mt, dqv);
И, как следствие, устройство функции proc_arg() немного усложнено:
void* MainTask::proc_arg()
{
assert(argno<=int(args.size()));
if (argno==int(args.size())) args.push_back(newArg(gmp));
return args[argno++].get();
}
Необходимость разбиения на этапы возникает из желания эффективным и естественным образом организовать сканирование и последующее сравнение old_dir и new_dir директорий:
mt.oldDir и mt.newDir соответственно. Дополнительное количество потоков не используется в силу того, что заведение отдельных объектов DirCont для каждого из них с последующим объединением содержимого заметно усложнит структуру программы, вряд ли существенно ускорив ее выполнение.
Кстати сказать, проверка данной гипотезы является неплохим упражнением для самостоятельного изучения MT программирования -- возьметесь?! Вот и мне тоже лень...
hash_vec-рам с именам, т.к. их содержимое уже никем не изменяется.
Как можно видеть, без разбиения на этапы потокам пришлось бы синхронизировать свой доступ к hash_vec-рам, что неприемлемо с точки зрения правильного MT дизайна.
DirCont использует свой собственный пул для имен директорий и файлов:
struct DirCont {
mem_pool ownmp;
sh_text name;
hash_vec<sh_text, char> dirs;
hash_vec<sh_text, unsigned long> files;
DirCont(const ch_rng& nm) : name(nt(ownmp, nm)), dirs(101), files(1001)
{}
};
Здесь мы имеем тот редкий случай, когда в одной точке приложения одновременно сходятся несколько объектов mem_pool, принадлежащих разным потокам:
ownmp, принадлежащий соответствующей структуре mt.oldDir или mt.newDir
mp, являющийся временным личным объектом рабочего потока, создаваемым thread_pool-ом на время работы функции MainTask::proc()
Как следствие, doFindFiles() создает сохраняемые имена директорий и файлов с помощью ownmp:
void MainTask::doFindFiles(mem_pool& mp, data_queue&, Arg&, const FindFilesMsg&
msg)
{
int pref=msg.dir->name->size();
vector<sh_text> dirs;
for (dirs.push_back(msg.dir->name); dirs.size(); ) {
sh_dir shd=new_dir(mp, dirs.back());
dirs.pop_back();
for (dir::entry dent(mp); shd->find_next(dent); ) {
if (dent.name=="." || dent.name=="..") continue;
sh_text fname=shd->full_name(dent);
if (dent.isdir) dirs.push_back(fname);
assert(fname->size()>=pref+1);
int beg= (fname->begin()[pref]==pathSepr) ? pref+1 : pref;
sh_text name(nt(msg.dir->ownmp, fname->begin()+beg, fname->end()));
if (dent.isdir) msg.dir->dirs.insert(name, 0);
else msg.dir->files.insert(name, dent.size);
}
}
}
А doCompare() и doCopyFile() запоминают найденные имена (факт. ключи hash_vec<sh_text, ...>-ра) по ссылке, а не значению:
const sh_text& dir=dc1->dirs.key(i);
// ...
const sh_text& fil=dc1->files.key(i);
// ...
const sh_text& name=oldDir.files.key(msg.oldPos);
Т.к. сохранение по значению приведет к копированию объекта sh_ptr<text> и, как следствие, одновременному использованию ownmp несколькими рабочими потоками. Тем самым в программе появится ошибка синхронизации, т.е. та самая "великая и ужасная" race condition, непонятно когда и как проявляющаяся.
И если желаете, то в качестве неприятного, но весьма поучительного упражнения можно и в самом деле заменить ссылки на значения и попытаться ее отследить...
diff_dir/mod/... может потребовать предварительного создания недостающих промежуточных поддиректорий. Задача осложняется еще и тем, что подлежащие созданию поддиректории могут быть созданы параллельно работающими потоками в промежутке между временем обнаружения их отсутствия и попыткой их создать. Для эффективного решения данной проблемы приложение пробует сразу же создать несуществующий файл и только в случае ошибки выполняется попытка создания промежуточных директорий и повторная попытка создания файла:
file fout(mp);
if (!fout.open(msg.toName, file::wro, file::crt|file::trnc)) {
make_dirs(mp, get_path(mp, msg.toName));
fout.ex_open(msg.toName, file::wro, file::crt|file::trnc);
}
Обратите внимание, что для повторного создания файла вместо функции open() используется вызов ex_open(), автоматически возбуждающей исключения.
На сегодняшний день можно констатировать, что ее размер и сложность устройства требуют описания, заметно превосходящего по объему весь данный материал, что и планируется сделать в будущем. Но на данный момент я принял решение выложить статью без подробного описания derslib. Надеюсь, что приведенные выше примеры многопоточных программ достаточно хорошо иллюстрируют ее основные возможности, давая начальный толчок в желании самостоятельно разобраться в деталях.
И не бойтесь самостоятельно экспериментировать! Гораздо лучше засучить рукава и быстро внести пробные изменения в исходный код, нежели долго размышлять: "зачем все так сложно?" и "этот кусок можно смело выбрасывать"...
Основная идея проста и уже была недвусмысленно выделена в самом начале: Правильное MT приложение -- это прежде всего правильный дизайн, РАЗРЕШАЮЩИЙ параллельное одновременное исполнение! И если начистоту, то одной лишь этой идеи будет вполне достаточно для существенного улучшения качества вашего MT кода. Самое сложное -- это действительно ей следовать, не позволяя себе проектировать в рамках щедро рассыпанных mutex-ов. Иметь мужество пересмотреть "давно известные истины".
Хотим мы, или не хотим, но наступает эра многоядерных/многопроцессорных систем, способных эффективно исполнять правильно спроектированные приложения. Или же демонстрировать ужасную производительность привычных решений -- выбор за нами!
Хорошая новость заключается в том, что при правильном подходе к делу создание многопоточных приложений превращается в довольно предсказуемое и в целом приятное дело, т.к. весь хаос и сложность параллельного исполнения надежно скрываются в деталях реализации небольшого количества стандартных интерфейсов. Но не буду кривить душой: создание реализаций таких интерфейсов и в самом деле является весьма нетривиальным процессом! И он действительно настолько сложен, насколько принято пугать! Так, например, над хорошим решением некоторых типичных задач (вроде Win32 реализации cond_var-ов) уже чуть ли не десятилетиями (!!!) идут баталии, а в промышленно используемых библиотеках нередко встречаются давно известные проблемы вроде пресловутого double-checked locking-а. И тем не менее: использование правильного подхода к делу удивительным образом упрощает задачу, а прирост производительности в десятки и сотни раз не может не изумлять!
Надеюсь, что результаты ваших личных экспериментов с многопоточным программированием помогут и вам открыть всю прелесть и изящество данной традиционно "тоскливой" темы, дерзайте!
Никакая часть данного материала не может быть использована в коммерческих целях без письменного разрешения автора.